 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFLaG: Fine-Grained Latent Grouping for Hallucination Detection
May 29, 2026Hallucinations in large language models (LLMs) arise from heterogeneous failure mechanisms, making reliable detection difficult for any single global uncertainty score. In this work, we formulate hallucination detection as a mechanism-aware evidence aggregation problem, where diverse representation- and token-level signals must be interpreted under multiple latent explanations. We propose FLaG, a lightweight hallucination detection framework that models correctness through a set of latent evidence groups. Each instance is softly associated with multiple groups via an energy-based routing mechanism, and group-conditional reliability signals are combined through a principled log-marginal aggregation. This design enables FLaG to capture heterogeneous hallucination patterns while remaining invariant to decision thresholds and evaluation metrics. The framework operates as a frozen-model head, requires no modification to the underlying language model, and incurs minimal computational overhead. We further provide a theoretical perspective that connects FLaG to optimal evidence aggregation under heterogeneous error mechanisms, showing that the Bayes-optimal test statistic necessarily admits a log-marginal form and that FLaG constitutes a tractable approximation with a controllable error bound. Extensive experiments across multiple benchmarks and LLM backbones demonstrate that FLaG consistently achieves SOTA performance, while exhibiting robust transfer across datasets and models, and remaining effective under limited supervision.
EvoRubric: Self-Evolving Rubric-Driven RL for Open-Ended Generation
May 28, 2026Reinforcement Learning (RL) has significantly advanced Large Language Models (LLMs) in verifiable domains, but aligning models for open-ended generation remains profoundly challenging due to the lack of definitive rewards. Current rubric-based RL methods mitigate this by employing explicit criteria; however, they rely heavily on static, human-annotated rubrics that inevitably cause policy lag, or expensive external proprietary models for dynamic updates. In this paper, we propose EvoRubric, a novel single-policy co-evolutionary RL framework that eliminates the reliance on static criteria and on external rubric generators. By unifying response generation and rubric generation under a single parameterized policy, EvoRubric dynamically alternates between a Reasoner and a Rubric Generator. To prevent reward hacking and ensure the reliability of generated signals, we introduce a multi-level verification pipeline featuring a meta-verifier, zero-variance pruning, and a Leave-One-Out peer consensus mechanism. Validated criteria are dynamically archived into a memory pool, yielding dense, multi-objective rewards to continuously co-optimize both roles. Extensive experiments across Medical, Writing, and Science domains demonstrate that EvoRubric consistently outperforms traditional static and external-LLM-driven alignment methods. Notably, our framework is compatible with human-expert priors. When initialized with expert-annotated rubrics, EvoRubric can further uncover novel, discriminative dimensions, achieving better performance than relying solely on static expert annotations.
OccuBench: Evaluating AI Agents on Real-World Professional Tasks via Language World Models
Apr 13, 2026AI agents are expected to perform professional work across hundreds of occupational domains (from emergency department triage to nuclear reactor safety monitoring to customs import processing), yet existing benchmarks can only evaluate agents in the few domains where public environments exist. We introduce OccuBench, a benchmark covering 100 real-world professional task scenarios across 10 industry categories and 65 specialized domains, enabled by Language World Models (LWMs) that simulate domain-specific environments through LLM-driven tool response generation. Our multi-agent synthesis pipeline automatically produces evaluation instances with guaranteed solvability, calibrated difficulty, and document-grounded diversity. OccuBench evaluates agents along two complementary dimensions: task completion across professional domains and environmental robustness under controlled fault injection (explicit errors, implicit data degradation, and mixed faults). We evaluate 15 frontier models across 8 model families and find that: (1) no single model dominates all industries, as each has a distinct occupational capability profile; (2) implicit faults (truncated data, missing fields) are harder than both explicit errors (timeouts, 500s) and mixed faults, because they lack overt error signals and require the agent to independently detect data degradation; (3) larger models, newer generations, and higher reasoning effort consistently improve performance. GPT-5.2 improves by 27.5 points from minimal to maximum reasoning effort; and (4) strong agents are not necessarily strong environment simulators. Simulator quality is critical for LWM-based evaluation reliability. OccuBench provides the first systematic cross-industry evaluation of AI agents on professional occupational tasks.
Supervised Fine-Tuning Needs to Unlock the Potential of Token Priority
Feb 01, 2026The transition from fitting empirical data to achieving true human utility is fundamentally constrained by a granularity mismatch, where fine-grained autoregressive generation is often supervised by coarse or uniform signals. This position paper advocates Token Priority as the essential bridge, formalizing Supervised Fine-Tuning (SFT) not as simple optimization but as a precise distribution reshaping process that aligns raw data with the ideal alignment manifold. We analyze recent breakthroughs through this unified lens, categorizing them into two distinct regimes: Positive Priority for noise filtration and Signed Priority for toxic modes unlearning. We revisit existing progress and limitations, identify key challenges, and suggest directions for future research.
ICX360: In-Context eXplainability 360 Toolkit
Nov 14, 2025Large Language Models (LLMs) have become ubiquitous in everyday life and are entering higher-stakes applications ranging from summarizing meeting transcripts to answering doctors' questions. As was the case with earlier predictive models, it is crucial that we develop tools for explaining the output of LLMs, be it a summary, list, response to a question, etc. With these needs in mind, we introduce In-Context Explainability 360 (ICX360), an open-source Python toolkit for explaining LLMs with a focus on the user-provided context (or prompts in general) that are fed to the LLMs. ICX360 contains implementations for three recent tools that explain LLMs using both black-box and white-box methods (via perturbations and gradients respectively). The toolkit, available at https://github.com/IBM/ICX360, contains quick-start guidance materials as well as detailed tutorials covering use cases such as retrieval augmented generation, natural language generation, and jailbreaking.
Thinking with Video: Video Generation as a Promising Multimodal Reasoning Paradigm
Nov 06, 2025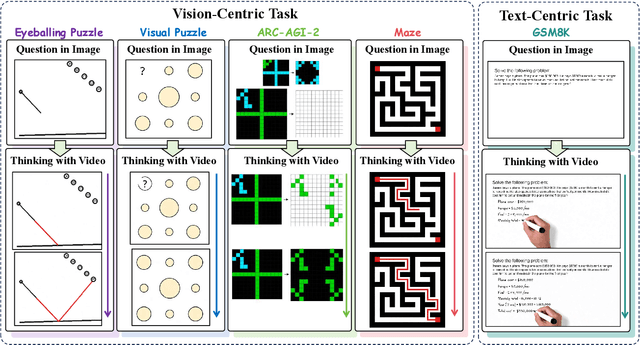
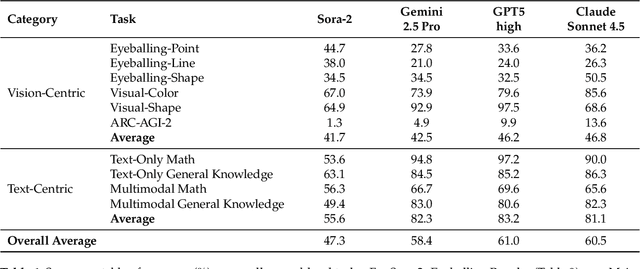
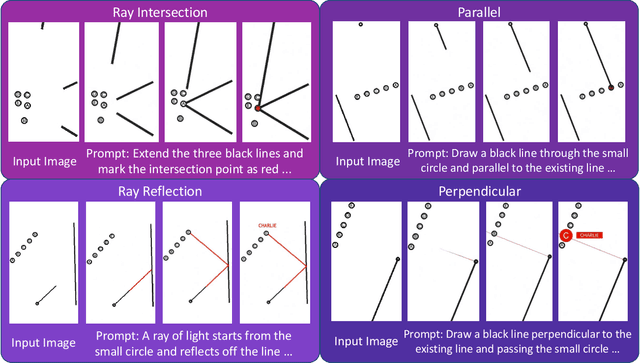

"Thinking with Text" and "Thinking with Images" paradigm significantly improve the reasoning ability of large language models (LLMs) and Vision Language Models (VLMs). However, these paradigms have inherent limitations. (1) Images capture only single moments and fail to represent dynamic processes or continuous changes, and (2) The separation of text and vision as distinct modalities, hindering unified multimodal understanding and generation. To overcome these limitations, we introduce "Thinking with Video", a new paradigm that leverages video generation models, such as Sora-2, to bridge visual and textual reasoning in a unified temporal framework. To support this exploration, we developed the Video Thinking Benchmark (VideoThinkBench). VideoThinkBench encompasses two task categories: (1) vision-centric tasks (e.g., Eyeballing Puzzles), and (2) text-centric tasks (e.g., subsets of GSM8K, MMMU). Our evaluation establishes Sora-2 as a capable reasoner. On vision-centric tasks, Sora-2 is generally comparable to state-of-the-art (SOTA) VLMs, and even surpasses VLMs on several tasks, such as Eyeballing Games. On text-centric tasks, Sora-2 achieves 92% accuracy on MATH, and 75.53% accuracy on MMMU. Furthermore, we systematically analyse the source of these abilities. We also find that self-consistency and in-context learning can improve Sora-2's performance. In summary, our findings demonstrate that the video generation model is the potential unified multimodal understanding and generation model, positions "thinking with video" as a unified multimodal reasoning paradigm.
Qwen3Guard Technical Report
Oct 16, 2025As large language models (LLMs) become more capable and widely used, ensuring the safety of their outputs is increasingly critical. Existing guardrail models, though useful in static evaluation settings, face two major limitations in real-world applications: (1) they typically output only binary "safe/unsafe" labels, which can be interpreted inconsistently across diverse safety policies, rendering them incapable of accommodating varying safety tolerances across domains; and (2) they require complete model outputs before performing safety checks, making them fundamentally incompatible with streaming LLM inference, thereby preventing timely intervention during generation and increasing exposure to harmful partial outputs. To address these challenges, we present Qwen3Guard, a series of multilingual safety guardrail models with two specialized variants: Generative Qwen3Guard, which casts safety classification as an instruction-following task to enable fine-grained tri-class judgments (safe, controversial, unsafe); and Stream Qwen3Guard, which introduces a token-level classification head for real-time safety monitoring during incremental text generation. Both variants are available in three sizes (0.6B, 4B, and 8B parameters) and support up to 119 languages and dialects, providing comprehensive, scalable, and low-latency safety moderation for global LLM deployments. Evaluated across English, Chinese, and multilingual benchmarks, Qwen3Guard achieves state-of-the-art performance in both prompt and response safety classification. All models are released under the Apache 2.0 license for public use.
Flow-CDNet: A Novel Network for Detecting Both Slow and Fast Changes in Bitemporal Images
Jul 03, 2025Change detection typically involves identifying regions with changes between bitemporal images taken at the same location. Besides significant changes, slow changes in bitemporal images are also important in real-life scenarios. For instance, weak changes often serve as precursors to major hazards in scenarios like slopes, dams, and tailings ponds. Therefore, designing a change detection network that simultaneously detects slow and fast changes presents a novel challenge. In this paper, to address this challenge, we propose a change detection network named Flow-CDNet, consisting of two branches: optical flow branch and binary change detection branch. The first branch utilizes a pyramid structure to extract displacement changes at multiple scales. The second one combines a ResNet-based network with the optical flow branch's output to generate fast change outputs. Subsequently, to supervise and evaluate this new change detection framework, a self-built change detection dataset Flow-Change, a loss function combining binary tversky loss and L2 norm loss, along with a new evaluation metric called FEPE are designed. Quantitative experiments conducted on Flow-Change dataset demonstrated that our approach outperforms the existing methods. Furthermore, ablation experiments verified that the two branches can promote each other to enhance the detection performance.
ALPS: Attention Localization and Pruning Strategy for Efficient Alignment of Large Language Models
May 24, 2025



Aligning general-purpose large language models (LLMs) to downstream tasks often incurs significant costs, including constructing task-specific instruction pairs and extensive training adjustments. Prior research has explored various avenues to enhance alignment efficiency, primarily through minimal-data training or data-driven activations to identify key attention heads. However, these approaches inherently introduce data dependency, which hinders generalization and reusability. To address this issue and enhance model alignment efficiency, we propose the \textit{\textbf{A}ttention \textbf{L}ocalization and \textbf{P}runing \textbf{S}trategy (\textbf{ALPS})}, an efficient algorithm that localizes the most task-sensitive attention heads and prunes by restricting attention training updates to these heads, thereby reducing alignment costs. Experimental results demonstrate that our method activates only \textbf{10\%} of attention parameters during fine-tuning while achieving a \textbf{2\%} performance improvement over baselines on three tasks. Moreover, the identified task-specific heads are transferable across datasets and mitigate knowledge forgetting. Our work and findings provide a novel perspective on efficient LLM alignment.
LeTS: Learning to Think-and-Search via Process-and-Outcome Reward Hybridization
May 23, 2025Large language models (LLMs) have demonstrated impressive capabilities in reasoning with the emergence of reasoning models like OpenAI-o1 and DeepSeek-R1. Recent research focuses on integrating reasoning capabilities into the realm of retrieval-augmented generation (RAG) via outcome-supervised reinforcement learning (RL) approaches, while the correctness of intermediate think-and-search steps is usually neglected. To address this issue, we design a process-level reward module to mitigate the unawareness of intermediate reasoning steps in outcome-level supervision without additional annotation. Grounded on this, we propose Learning to Think-and-Search (LeTS), a novel framework that hybridizes stepwise process reward and outcome-based reward to current RL methods for RAG. Extensive experiments demonstrate the generalization and inference efficiency of LeTS across various RAG benchmarks. In addition, these results reveal the potential of process- and outcome-level reward hybridization in boosting LLMs' reasoning ability via RL under other scenarios. The code will be released soon.